


Alexa is great, providing amazing features to control apps and services with just your voice. But it’s understanding of non-American accents leaves much to be desired. Case in point - using Alexa with my Indian accent brings out some serious problems. No matter how many times I try to say “sprint”, it would only understand it as “spend”.
This is terrifying for Alexa developers like me who want to use the NLP power of Alexa to build solutions that cater primarily to the Indian population. Amazon does offer to develop Alexa skill in ‘EN-IN’ but it does not solve the problem. This major flaw in transcribing Indian accent results in a failure in the skill flow and broken conversations.
But should it be a roadblock for you to develop an Alexa skill?
No, because we found a way to solve this problem.
Devising a Solution
The solution is to use the ability to add synonyms for slot values (in custom slot types).
In any Alexa skill, you can add intents and each intent has different slots. You can choose pre-defined AMAZON slot types for your slots or you can create custom slot types. The difference between using AMAZON slot types and custom slot types is when you create a custom slot type, it allows you to add synonyms of slot values.
Using an example from our Alexa skill -
If we added “spend” as a synonym to “sprint” slot value, it would solve our problem. The next time Alexa hears “spend”, it would send slot value as “sprint” and that can be sent to the Lambda function which gives the back an appropriate response.
Quick aside: Our skill now available for beta testing, so do try it out.

This was the exact solution we were looking for.
Now we had the solutions and two ways to make it happen :
-
Manually add synonyms for each slot value based on user data and custom reviews.
-
Predict synonyms for each slot values and automatically add them once-twice a week.
The manual additions are quite easy to do, but not a scalable option. Consider a case where you have more than 50 slot values and you want to add slot synonyms to each one or most of them. Doing it manually would be tedious.
This is the reason we went with the Predictive approach and automated the addition of slot synonyms in our skill.
Implementing the Solution
To automate the prediction and addition of slot synonyms, we used following AWS resources :
-
Lambda function
-
EC2 Instance
-
S3 bucket
- Alexa developers account
Now, that all the resources are ready, there are three main steps in the Predictive approach :
1. Capturing words like “spend” which are poorly transcribed by Alexa
2. Predicting the slot value the word “spend” belongs to.
3. Adding the word “spend” as a synonym to the predicted slot values.
I will explain steps 1 and 3 in a while, but let’s understand step 2 as it’s the most crucial step.
Prediction requires a machine learning algorithm. In our case, we have used Scalar Vector Machines(SVM) to predict the slot value. It’s one of the simplest yet quite accurate ML algorithm used for text classification.
SVM is a supervised ML algorithm which finds the line or hyperplane with the maximum distance from scalar vectors. Say, you have two classes -
a. Words similar to “sprint”
b. Words similar to “release”
Using SVM, we can find the line which clearly distinguishes these two classes based on the available training dataset. This line will be the maximum distance from the words which are on the outermost part of the clusters or so-called as scalar vectors.
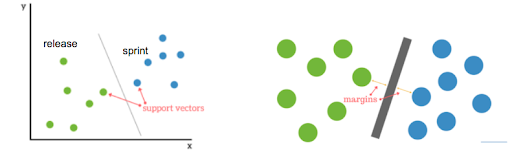
You can learn more about SVM here
The Architecture
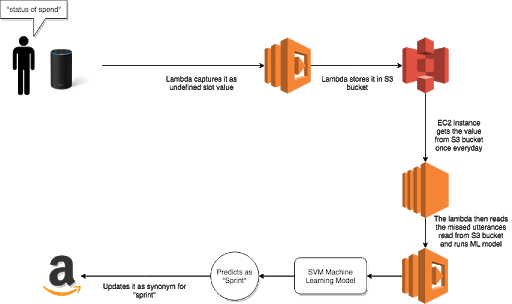
Step 1
To capture the poorly transcribed words such as “spend”, we use our Lambda function to read the request JSON from Alexa and store the word along with its slot name in a CSV file, and store it in S3 bucket.
def checkutterance(data):
result = []
for k, v in data.items():
if "resolutions" in v.keys():
for i in v["resolutions"]["resolutionsPerAuthority"]:
if i["status"]["code"] == "ER_SUCCESS_NO_MATCH":
result.append({"slot": v["name"], "utterance": v["value"]})
s3 = boto3.client('s3')
response = s3.get_object(Bucket="BUCKET_NAME", Key="FILE_NAME")
data = response['Body'].read().decode('utf-8')
string = ""
for j in result:
string = string + json.dumps(j) + "\n"
data = data + string
encoded = data.encode('utf-8')
s3.put_object(Body=encoded, Bucket='BUCKET_NAME', Key='FILE_NAME')
Step 2
Once the missed values are stored in a S3 bucket, we use our EC2 instance to read the file.
In our case, we have scheduled a cron job to do it every day.
The script deployed on EC2 instance is responsible for training and predicting classes using SVM. The script reads the missed values from the file and predicts the class for each value. In our case, it predicts “spend” as a synonym for slot value “sprint”.
Here, we have also set a threshold value in case the slot value matches quite low to either of the class. Such values are again stored in a CSV file and mailed to us so that manually we can add them in the Alexa skill if required.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import boto3
from sklearn.pipeline import Pipeline
from sklearn import svm
from sklearn.utils import shuffle
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
text_clf = Pipeline([('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf-svm', svm.SVC(C=1, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=2, gamma='auto', kernel='rbf',
max_iter=-1, probability=True,
tol=0.001, verbose=False),),
])
Step 3
Once the slot value is predicted for each word, using Alexa cli, we update the word as a synonym for the respective slot in the Interaction Model JSON of our Alexa skill.
os.system('ask api get-model -s ALEXA_SKILL_ID -l en-IN > alexamodel.json ')
time.sleep(5)
data_alexa = []
with open('alexamodel.json', 'r+') as f :
data_alexa = json.load(f)
for i in data_alexa["interactionModel"]["languageModel"]["types"]:
if i["name"] == "choose":
for j in i["values"]:
if j["name"]["value"] =="sprint":
synonyms = j["name"]["synonyms"]
for s in sprint:
if s["utterance"] not in synonyms:
synonyms.append(s["utterance"])
print("new list of synonyms " , synonyms)
j["name"]["synonyms"] = synonyms
if j["name"]["value"] == "release":
synonyms = j["name"]["synonyms"]
for r in release:
if r["utterance"] not in synonyms:
synonyms.append(r["utterance"])
print("new list of synonyms " , synonyms)
j["name"]["synonyms"] = synonyms
with open('alexa.json', 'w+') as fp :
json.dump(data_alexa, fp,ensure_ascii=False)
fp.close()
os.system("ask api update-model -s ALEXA_SKILL_ID -f alexa.json -l en-IN")
The Alexa skill is then built using the same skill and hence automating the process of updating synonyms in our Alexa skill.
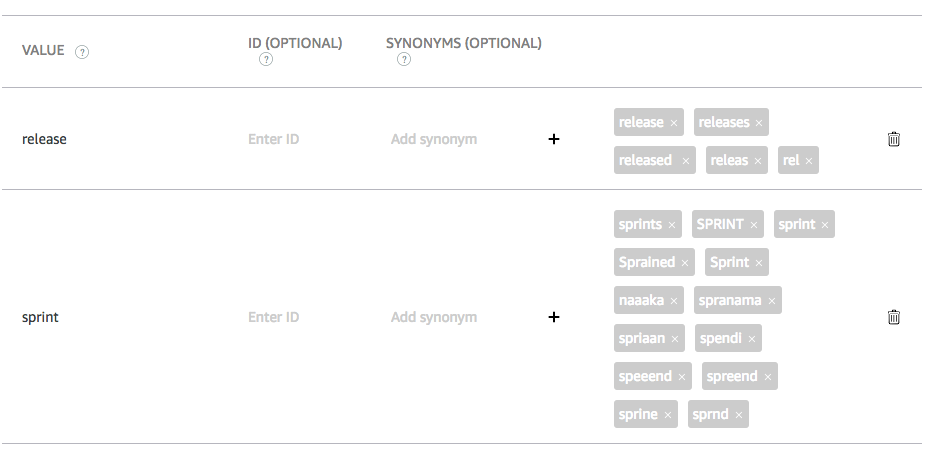
With this, the problem of transcribing Indian accent with Alexa skill has been solved to some extent. We are continuously updating our training dataset to improve the accuracy of our model.
If you have any suggestions on how to improve an Alexa skill for this particular problem, do let us know in the comments section below.