Semantic Search can be defined as a way to perform a search query beyond the traditional keyword search. It is a method which relies on understanding the contextual meaning of the query and shows results from a wide range of resources. This search strategy mimics the human way of searching or looking for something - just like the way we understand the content and then look for it or try to relate it.
For a Digital Asset Management (DAM) company, semantic search can enable a powerful way to search and locate the right content. It can help content creators and editors in scaling the content discovery process from a pile of thousands or millions of content, saving tons of time, eventually making life a lot easier.
In this article, we will be looking at various steps from a solution, implementation, and deployment standpoint needed to build a semantic image search-based Information Retrieval (IR) system over a cloud infrastructure. There are a couple of abstractions, terminologies, and out-of-the-box machine learning capabilities we will be looking at.
Problem Definition
Manually searching images is a tedious time consuming and error-prone task, especially if the number of available images is high and unorganized. In this scenario, it is important to make image data searchable using semantic search, where users can enter their query as a text, in natural language.
Objective
The proposed solution is to build a semantic image search for image retrieval, using an intelligent IR system. Ai and ML-based Natural language processing (NLP) and computer vision will be used to relate text entered as a search query with all the images stored in a DAM.
Solution
Here we describe the key steps to build a semantic image search-based IR system using out-of-the-box AI and ML services over a cloud infrastructure.
Step 1
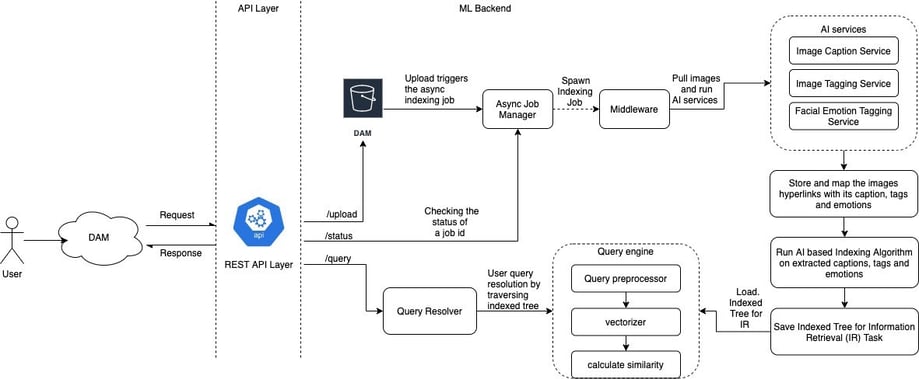
Upload images into a repository. For example, this repository could be an s3 bucket where a user can upload all the images as a data source. Use the REST API as a service layer to upload the image data synchronously. The below diagram shows the high-level view.
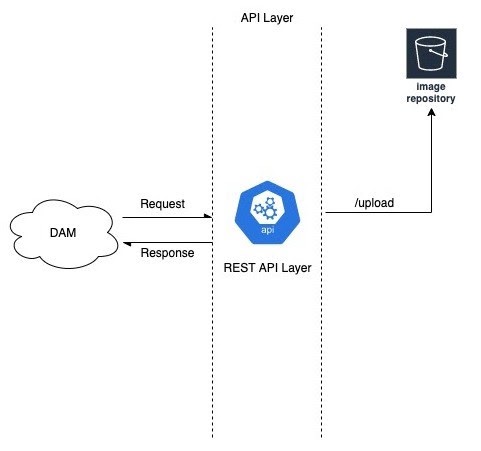
High-level architecture for a file uploader
Step 2
Once the upload is complete, an asynchronous job will be created automatically where a user will get the job id as a response. The newly created job_id is registered into the Job manager with status as “Pending”.
This job_id can be used later for tracking the status of the background indexing job. Below are some of the briefings about the inner workings of the job which will be performed during the indexing process (machine learning model training).
Part 1: Feature extraction phase
This part will cover the various steps to pull out features from image data using machine learning and deep learning-based AI services. There are a lot of ML services that are already available and can be easily integrated and used as a third party service. Apart from that, one can also create a custom solution if required. We will be using multiple out-of-the-box ML services that need to be further explored as required.
Step 2.1: Pull the images data from the repository where the data source resides. In our case, this repository is an S3 bucket where all images are stored using step 1.
Step 2.2: Run the image captioning algorithm over all the pulled images in step 2.1. This algorithm will determine the image caption for an image where the caption will be a one-sentence description for an image.
Step 2.3: Run object detection algorithm over all of the pulled images in step 2.1. This algorithm will determine the objects which are present in the image like a bat, ball, player, etc which can also be called tags for an image.
Step 2.4: Run an emotion detection algorithm over all the pulled images in step 2.1. This algorithm will determine the emotion for any face if present in the image. In case multiple faces will be there in the image then it will output emotions for all those faces.
Step 2.5: Collect all the results from step 2.2, step 2.3 as well as from step 2.4 and map them together with their respective image ids/hyperlinks.
Step 2.6: Store the results collected in step 2.5 in some persistent database. For example, we can use the AWS DynamoDB database to store all the collected results.
Part 2: Feature vectorization phase
This part will cover the details about converting text data into a numerical vector to make the mathematical computation possible over textual data.
Step 2.6.1: Load the pre-trained Sentence Encoder model in memory. The Sentence Encoder model is a pre-trained NLP model used to convert the sentence text into an N-dimensional numerical vector. This N-dimensional numerical vector represents the learned representation of a sentence text which can be used to compare two sentences easily in N-dimensions numerically based on their semantics/meanings, rather than comparing two sentences on a word or character overlapping level which is generally used for calculating the similarity between two sentences or text.

Step 2.7: Pull all the saved data in Step 2.5 for each of the images. This data will consist of all images mapped with their caption, tags/objects, and facial emotions which were extracted in previous steps.
Step 2.8: For each of the records pulled, concatenate the caption, tags, and facial emotion text into a single string of text.

Step 2.9: Pass the result collected in Step 2.8 through the Sentence encoder model loaded in Step 2.6. This will convert the string data into numerical representations such that those numerical representations represent the semantics of the text data as well which enables the semantic comparison between the two strings.

Step 2.10: Store the results produced in the previous steps in some persistent database. For example, We can use Redis as a persistent database to store these results. Redis gives the fast recall of the stored vectorized data at the time when needed, this makes it a good choice in terms of achieving high scalability.
Part 3: Running Indexing algorithm
This part will cover a brief overview of the indexing over vectorized text data. There can be multiple ways to implement an Indexing Algorithm using multi-level hierarchical clustering, binary tree / B+ tree-based ordering, etc which needs to be further explored as required.
Step 2.11: Pull the data stored in Step 2.10 from the database and run the indexing algorithm on top of this Data. The indexing algorithm creates tree-based indexing by performing some numerical computations over the calculated vectors for each of the images such that similar images lie more closer to each other in the tree. Once the indexing algorithm is completed successfully, the indexed tree is saved as a trained machine learning model which can be later used for information retrieval (IR) tasks.

Step 2.12: After completing Step 2.11, update the job_id in Job manager as “completed”.
Step 3: Load the saved (trained) indexing model and sentence encoder model into memory and prepare the query engine for resolving queries. The query engine is a function that takes a text-based user query and converts it into a vector by passing it through the sentence encoder model. Once the user query gets converted to vector form, this vector is compared with other image vectors stored in an indexed tree for all images in the DAM. Comparison is performed by traversing the indexed tree in O(log n) time which is very fast and can easily handle even the records in millions. We can also use Dynamic programming as a way to even further optimize our traversal time by remembering the paths using some rules. Once the traversing is completed, most similar results are returned as the top similar images based on their semantic similarity.
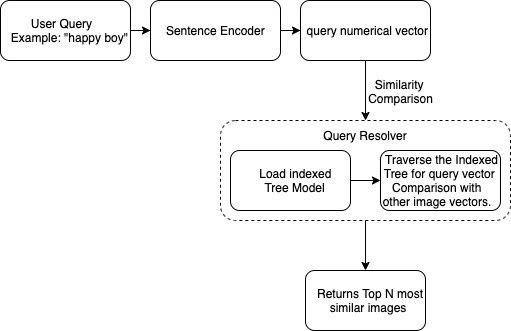
Solution Overview
Consolidating all the above steps, below is the solution architecture that summarizes and showcases a high-level peek into the overall flow of how the user journey will look like from a DAM to our Machine Learning backend Layer. It also shows some common endpoints and their integrations with various key components that will be part of the main pipeline.