


In a big data system, the volume of data produced every second is very high. Owing to this, enterprises feel the need for platforms, technologies, and frameworks to help them handle this data effectively and efficiently. Kafka is one such framework and is one of the important tools in the big data ecosystem. It is a distributed streaming platform that can ingest and process large volumes of data.
Producer, Admin, and Consumers are the three different types of Kafka clients. Consumers read the streams, process, and forward it to some other Kafka topics or persistence storage. Using consumers efficiently is very important in Kafka. If data is produced faster than it is consumed then this introduces a lag in the system because the data is not being processed in real-time. To tackle this problem we use the Kafka Consumer group. In this blog, we will cover the crucial concepts of consumer group partitioning, rebalancing, and consumer lag in a nutshell.
Introduction to Consumer Group
Ensembling multiple consumers in Kafka is called Consumer Group. With this, the data is divided into equal numbers of consumers in the group. Consumers within a group have the same group id. Let us understand how to create and manage consumer groups with an example.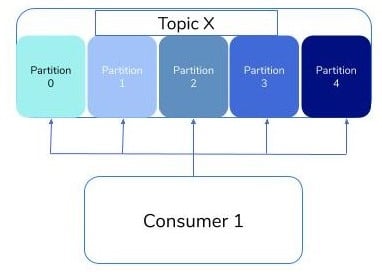
In the above diagram, we can see that a single consumer is trying to read the data from multiple partitions. This causes a bottleneck in processing information and introduces a lag. 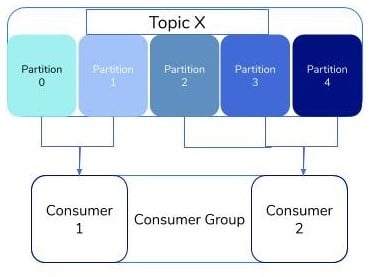
Preventing this lag is rather easy. When using the consumer group, the partitions are divided into consumers equally. This helps us to achieve more throughput and processing of the data. Here, we have 2 consumers in the same consumer group and each consumer is processing the data from the two different sets of partitions for the given topic. At max, the number of consumers in the group should be equal to the number of partitions in the topic. If the number of consumers is greater than the number of partitions, the extra consumers are not used in the application. Kafka does not assign the same partition to multiple consumers in the same group.
Re-balancing
Whenever consumers are added or removed, rebalancing occurs in the group, or the number of partitions is modified. During rebalancing, the reassignment of the partitions to the consumer is performed by the group coordinator to ensure high availability and scalability.
During the rebalancing period, the consumer group will not be able to process the data until the rebalancing is achieved. Closing the consumer properly reduces the time needed to rebalance the group.
The group coordinator is a Kafka broker. For each Kafka group, you can have a different group coordinator for different consumer groups. The first consumer to join the group is called the group leader and receives all the consumers from the group coordinator. The group leader then assigns the partition to each consumer. Each consumer can see only their assigned partitions. The only leader knows the full list of consumers and their partition assignment
The failure of some consumers during the runtime in the group is determined by the group coordinator. Every consumer in the group must send a heartbeat to the group coordinator. If the group coordinator doesn’t receive the heartbeat for the time mentioned in the session.timeout.ms, it assumes the consumer is down and initiates the rebalancing.
During threading in an application, the consumer must belong to only a single thread and a thread can only contain a single consumer to be thread-safe.
Partition Assignment in Consumer Group
A leader is responsible for assigning the partitions to all the consumers in the group. It has two partition assignment policies built into it, which are:
- Range
- In this assignment policy, consumers are assigned a consecutive subset of the partitions.
- If two consumers C0 and C1 subscribe to two topics T1 and T2 with 3 partitions each then C0 will be assigned 0 and 1 partitions from T1 and T2, while C2 will only be assigned to partition 2 in both T1 and T2. The drawback of this scheme is that it doesn't split the partitions equally among consumers.
- Round Robin
- In this assignment of partition, consumers are assigned in a round robin manner. This ensures the equal assignment of partition to each consumer.
- If two consumers, C0 and C1 subscribe to two topics T1 and T2 with 3 partitions each then C0 will be assigned 0, 2 partitions from T1 and 1 from T2. While C2 will be assigned partition 1 from T1 and 0, 2 from topic T2.
We also can create the custom partitions by implementing partition.assignment.strategy.
Kafka Consumer Group Lag
Consumer lag is one of the most important metrics in kafka deployment. We need to calculate the time difference between the current consumer offset and the current topic offset.
Consumer lag is one of the most important metrics in Kafka deployment. We need to calculate the time difference between the current consumer offset and the current topic offset.
This metric will indicate how far behind the application is from processing the latest information. You may have an application that can accept large latency but our goal must be to keep the latency as small as possible. Measuring consumer lag is imprecise because there is no way to retrieve the current consumer offset and current topic partition offset in the same operation. For measuring the lag with minimal error your monitoring application must run a monitoring application job in parallel to measure both consumer offset and current topic offset.
Kafka continues to become popular among organizations as it allows them to have a huge number of messages without the drawbacks of performance or data loss via a distributed medium. When understanding Kafka from an architectural standpoint, it is important to choose the best method of deploying consumers should be thoroughly thought of. It is only then that an optimal strategy can be deployed for a scalable microservice. From multi availability zone deployment to implementing transactional systems, we have worked on Kafka for multiple clients. To explore what we can do for you, talk to our experts.