

We’ve talked quite a bit about data lakes in the past couple of blogs. We looked at what is a data lake, data lake implementation, and addressing the whole data lake vs. data warehouse question. And now that we have established why data lakes are crucial for enterprises, let’s take a look at a typical data lake architecture, and how to build one with AWS.
Before we get down to the brass tacks, it’s helpful to quickly list out what the specific benefits that we want an ideal data lake to deliver. These would be:
- The ability to collect any form of data, from anywhere within an enterprise’s numerous data sources and silos. From revenue numbers to social media streams, and anything in between.
- Reduce the effort needed to analyze or process the same data set for different purposes by different applications.
- Keep the whole operation cost efficient, with the ability to scale up storage and compute capacities as required, and independent of each other.
And with those requirements in mind, let’s see how to set up a data lake with AWS
Data Lake Architecture
A typical data lake architecture is designed to:
- take data from a variety of sources
- move them through some sort of processing layer
- make it available for consumption by different personas within the enterprise
So here, we have some key part of the architecture to consider:
Landing zone: This is the area where all the raw data comes in, from all the different sources within the enterprise. The zone is strictly meant doe data ingestion, and no modelling or extraction should be done at this stage.
Curation zone: Here’s where you get to play with the data. The entire extract-transform-load (ETL) process takes place at this stage, where the data is crawled to understand what it is and how it might be useful. The creation of metadata, or applying different modelling techniques to it to find potential uses, is all done here.
Production zone: This is where your data is ready to be consumed into different application, or to be accessed by different personas.
Data Lake architecture with AWS
With our basic zones in place, let’s take a look at how to create a complete data lake architecture with the right AWS solutions. Throughout the rest of this post, we’ll try to bring in as many of AWS products as applicable in any scenario, but focus on a few key ones that we think brings the best results.
Landing Zone - Data Ingestion & Storage
For this zone, let’s first look at the available methods for data ingestion:
- Amazon Direct Connect: Establish a dedicated connect between your premises or data centre and the AWS cloud for secure data ingestion. With an industry standard 802.1q VLAN, the Amazon Direct Connect offers a more consistent network connection for transmitting data from your on premise systems to your data lake.
- S3 Accelerator: Another quick way to enable data ingestion into an S3 bucket is to use the Amazon S3 Transfer Acceleration. With this, your data gets transferred to any of the globally spread out edge locations, and then routed to your S3 bucket via an optimized and secure pathway.
- AWS Snowball: You can securely transfer huge volumes of data onto the AWS cloud with AWS Snowball. It’s designed for large-scale data transport and is one-fifth of the cost of transferring data via high-speed internet. It’s a great option for transferring voluminous data assets like genomics, analytics, image or video repositories.
- Amazon Kinesis: Equipped to handle massive amounts of streaming data, Amazon Kinesis can ingest, process and analyze real-time data streams. The entire infrastructure is managed by AWS to that it’s highly efficient and cost-effective. You have:
- Kinesis Data Streams: Ingest real-time data streams into AWS from different sources and create arbitrary binary data streams that are on multiple availability zones by default.
- Kinesis Firehose: You can capture, transform, and quickly load data onto Amazon S3, RedShift, or ElasticSearch with Kinesis Firehose. The AWS managed system autoscales to match your data throughput, and can batch, process and encrypt data to minimize storage costs.
- Kinesis Data Analytics: One of the easiest ways to analyze streaming data, Kinesis Data Analytics pick any streaming source, analyze it, and push it out to another data stream or Firehose.
Storage - Amazon S3
One of the most widely used cloud storage solution, the Amazon S3 is perfect for data storage in the landing zone. S3 is a region level, multi availability zone storage options. It’s a highly scalable object storage solution offering 99.999999999% durability.
But capacity aside, the Amazon S3 is suitable for a data lake because it allows you to set a lifecycle for data to move through different storage classes.
- Amazon S3 Standard to store hot data that is being immediately used across different enterprise applications
- Amazon S3 Infrequent Access to hold warm data, that accessed less across the enterprise but needs to be accessed rapidly whenever required.
- Amazon S3 Glacier to archive cold data at a very low cost as compared to on premise storage.
Curation Zone - Catalogue and Search
Because information in the data lake is in the raw format, it can be queried and utilized for multiple different purposes, by different applications. But to make that possible, usable metadata that reflects technical and business meaning also has to be stored alongside the data. This means you need to have a process to extract metadata, and properly catalogue it.
The meta contains information on the data format, security classification-sensitive, confidential etc, additional tags-source of origin, department, ownership and more. This allows different applications, and even data scientists running statistical models, to know what is being stored in the data lake.
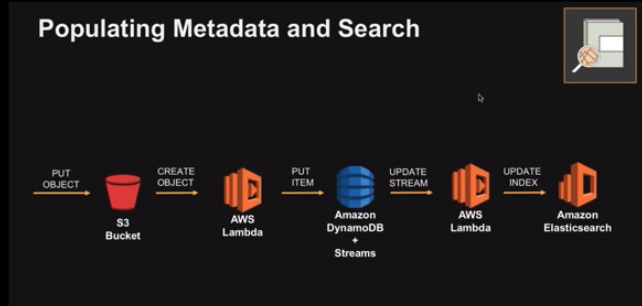
Source: Screengrab from "Building Data Lake on AWS", Amazon Web Services, Youtube
The typical cataloguing process involves lambda functions written to extract metadata, which get triggered every time object enters Amazon S3. This metadata is stored in a SQL database and uploaded to AWS ElasticSearch to make it available for search.
AWS Glue is an Amazon solution that can manage this data cataloguing process and automate the extract-transform-load (ETL) pipeline. The solutions runs on Apache Spark and maintains Hive compatible metadata stores. Here’s how it works:
- Define crawlers to scan data coming into S3 and populate the metadata catalog. You can schedule this scanning at a set frequency or to trigger at every event
- Define the ETL pipeline and AWS Glue with generate the ETL code on Python
- Once the ETL job is set up, AWS Glue manages its running on a Spark cluster infrastructure, and you are charged only when the job runs.
The AWS Glue catalog lives outside your data processing engines, and keeps the metadata decoupled. So different processing engines can simultaneously query the metadata for their different individual use cases. The metadata can be exposed with an API layer using API Gateway and route all catalog queries through it.
Curation Zone - Processing
Once cataloging is done, we can look at data processing solutions, which can be different based on what different stakeholders want from the data.
Amazon Elastic MapReduce (EMR)
Amazon’s EMR is a managed Hadoop cluster that can process a large amount of data at low cost.
A typical data processing involves setting up a Hadoop cluster on EC2, set up data and processing layers, setting up a VM infrastructure and more. However, this entire process can be easily handled by EMR. Once configured, you can spin up new Hadoop clusters in minutes. You can point them to any S3 to start processing, and the cluster can disappear once the job is done.
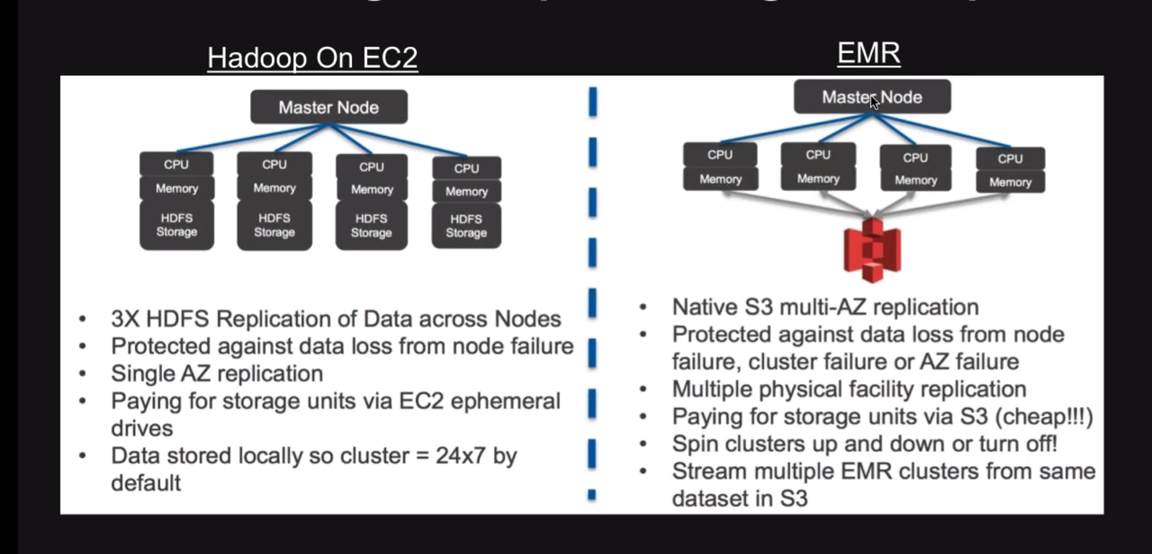
Source: Screengrab from "Building Data Lake on AWS", Amazon Web Services, Youtube
The primary benefit of processing with EMR rather than Hadoop on EC2 is the cost savings. With the latter, your data lies within the Hadoop processing cluster, which means the cluster needs to be up even when the processing job is done. So you are still paying for it. However with EMR, your data and processing layers are decoupled, allowing you to scale them both independent of each other. So while your data resides in S3, your Hadoop clusters on EMR can be set up and stopped as required, making the cost of processing completely flexible. Costs are also lowered by easily integrating it with Amazon spot instances for lower pricing.
Amazon ElasticSearch
This is another scalable managed search node cluster that can be easily integrated with other AWS services. It’s best for log analytics use cases.
Amazon RedShift
If you have a lot of BI dashboards and applications, Amazon RedShift is a great processing solution. It’s inexpensive, fully managed, and ensures security and compliance. With RedShift, you can spin up a cluster of compute nodes to simultaneously process queries.
This processing stage is also where enterprises can set up their sandbox. They can open up the data lake to data scientists to run preliminary experiments. Because data collection and acquisition is now taken care of, data scientists can focus on finding innovative ways to put the raw data to use. They can bring is open-source or commercial analytics tools to create required test beds, and work on creating new analytics models aligned with different business use cases.
Production Zone - Serve Processed Data
With processing, data lake is now ready to push out data to all necessary applications and stakeholders. So you can have data going out to legacy applications, data warehouses, BI applications and dashboards. This can be accessed by analysts, data scientists, business users, and other automation and engagement platforms.
So there you have it, a complete data lake architecture and how it can be set with the best-of-breed AWS solutions.
Looking to set up an optimal data lake infrastructure? Talk to our expert AWS team, and let’s find out how Srijan can help.