


Efficient data management is a key priority for enterprises today. And it’s not just to drive effective decision-making for business stakeholders, but also for a range of other business processes like personalization, IoT data monitoring, asset performance management and more.
Most enterprises are maturing out of their traditional data warehouses and moving to data lakes. In one of our recent posts, we covered what is a data lake, how it’s different from a data warehouse, and the exact advantages it brings to enterprises. Moving a step further, this post will focus on what enterprises can expect as they start their data lake implementation. This mostly centres around the typical data lake development and maturity path, as well as some key questions that enterprises will have to answer before and during the process.
Enterprise Data Lake Implementation - The Stages
Like all major technology overhauls in an enterprise, it makes sense to approach the data lake implementation in an agile manner. This basically means setting up a sort of MVP data lake that your teams can test out, in terms of data quality, storage, access and analytics processes. And then you can move on to adding more complexity with each advancing stage.
Most companies go through the basic four stages of data lake development and maturity
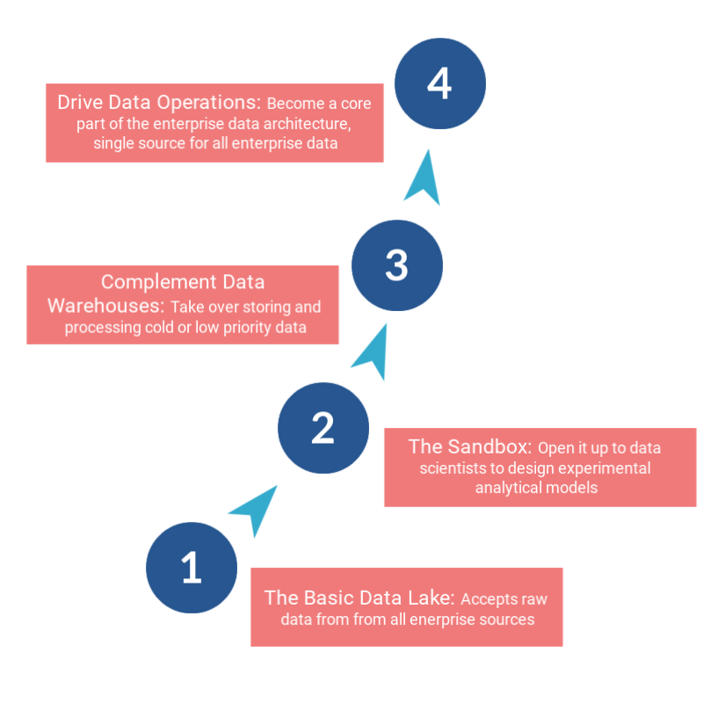
Stage 1 - The Basic Data Lake
At this stage you’ve just started putting the basic data storage functionality in place. The team working on setting up the data lake have made all the major choices in terms of using legacy or cloud-based technology for the data lake. They have also settled upon the right security and governance practices that you want to bake into the infrastructure.
With a plan in place, the team builds a scalable but currently low-cost data lake, separate from the core IT systems. It’s a small addition to your core technology stack, with minimal impact on existing infrastructure.
In terms of capability, the Stage 1 data lake can:
- Store raw data coming in from different enterprise sources
- Combine data from internal and external sources to provide enriched information
Stage 2 - The Sandbox
The next stage involves opening up the data lake to data scientists, as a sandbox to run preliminary experiments. Because data collection and acquisition is now taken care of, data scientists can focus on finding innovative ways to put the raw data to use. They can bring is open-source or commercial analytics tools to create required test beds, and work on creating new analytics models aligned with different business use cases.
Stage 3 - Complement Data Warehouses
The third stage of data lake implementation is when enterprises use it as complementary to existing data warehouses. While data warehouses focus on high-intensity extraction from relational databases, low-intensity extraction and cold or rarely used data is moved to the data lakes. This ensures that the data warehouses don’t exceed storage limits, while low priority data sets still get stored. The data lake offers an opportunity to generate insights from this data, or query it to find information not indexed by traditional databases.
Stage 4 - Drive Data Operations
The final stage of maturity is when the data lake become a core part of the enterprise data architecture, and actually drives all data operations. At this point, the data lake will have replaced other data stores and warehouses, and is now the single source of all data flowing through the enterprise.
The data lake now enables the enterprise to:
- Build complex data analytics programs that serve various business use cases
- Create dashboard interfaces that combine insights from the data lake as well as other application or sources
- Deploy advanced analytics or machine learning algorithms, as the data lake manages compute-intensive tasks
This stage also means that the enterprise has put in place strong security and governance measures to optimally maintain the data lake.
Points to Consider to Before Data Lake Implementation
While the agile approach is a great way to get things off the ground, there are always roadblocks that can kill the momentum on the data lake initiative. In most cases, these blocks are in the form of some infrastructural and process decisions that need to be made, to proceed with the data lake implementation.
Stopping to think about and answer these questions in the middle of the project can cause delays because now you also have to consider the impact of these decisions on work that’s already been done. And that’s just putting too many constraints into the project,
So here’s a look at a few key considerations to get out of the way, before you embark on a data lake project:
Pin Down the Use Cases
Most teams jump to technology considerations around a data lake as their first point of discussion. However, defining a few most impactful use cases for the data lake should take priority over deciding the technology involved. That’s because these defined use cases will help you showcase some immediate returns and business impact of the data lake. And that will be key to maintaining project support from the higher up the chain of command, and project momentum.
Physical Storage - Get It Right
The primary objective of the data lake is storing the vast amount of enterprise data generated, in their raw format. Most data lakes will have a core storage layer to hold raw or very lightly processed data. Additional processing layers are added on top of this core layer, to structure and process the raw data for consumption into different application and BI dashboards.
Now, you can have your data lake built on legacy data storage solutions like Hadoop or on cloud-based ones, as offered by AWS, Google or Microsoft. But given the amount of data being generated and leveraged by enterprises in recent times, the choice of data storage should consider:
- Your data lake architecture should be capable of scaling with your needs, and not run into unexpected capacity limits
- Should be designed to support structured, semi-structured and unstructured data all in a central repository
- Building a core layer that can ingest raw data, so a diverse range of schema can be applied as needed at the point of consumption
- Ideally decouple the storage and computation functions, allowing them to scale independently
Handling Metadata
Because information in the data lake is in the raw format, it can be queried and utilized for multiple different purposes, by different applications. But to make that possible, usable metadata that reflects technical and business meaning also has to be stored alongside the data. The ideal way is to have a separate metadata layer that allows for different schema to be applied on the right data sets.
A few important elements to consider while designing a metadata layer are:
- Make metadata creation mandatory for all data being ingested into the data lake from all sources
- You can also automate the creation of metadata by extracting information from the source material. This is possible if you are on a cloud-based data lake
Security and Governance
The security and governance of an enterprise data should be baked in the design from the start, and be aligned with the overall security and compliance practices within the enterprise. Some key pointers to ensure here:
- Data encryption, both for data in storage and in transit. Most cloud-based solutions provide encryption by default, for core and processed data storage layers
- Implementing network level restrictions to block big chunks of inappropriate access paths
- Create fine-grained access controls, in tandem with the organization-wide authentication and authorization protocols
- Create a data lake architecture that enforces basic data governance rules like the compulsory addition of metadata, or defined data completeness, accuracy, consistency requirements.
With these questions answered in advance, your data lake implementation will move at a consistent pace.
Interested in exploring how a data lake fits into your enterprise infrastructure? Talk to our expert team, and let’s find out how Srijan can help.