


What is a data pipeline? Why do we need it?
A data pipeline is a process of taking your raw data and transforming it into the final product: a set of reports that let you analyze your data in real-time. It has three components- A source, processing steps, and a destination. A data pipeline is a series of processing steps that enable data flow from the source to the destination.
Here are some common uses for a data pipeline:
1) Translating raw data into something that can be understood by humans and machines.
2) Creating reports based on the raw data.
3) Performing calculations on the raw data so that you can see what impact those calculations will have on other parts of your business.
There are different types of data out there—and not all of them are created equal. Some data is easy to collect and analyze; others are more difficult to get your hands on. And some types of data require specialized software or hardware to process properly.
While working with any data science problem, a data scientist has to deal with data in small, big, or huge quantities. If the problem is especially related to a deep learning context, then our data pipeline becomes one of the key elements of our entire training as well as the inference pipeline. Having an efficient, scalable as well as generic pipeline can handle a lot of hurdles to quickly create a neat prototype depending upon the type of data that we want to consume. With the advancement, affordability, and availability of massive hardware and systems like GPUs and TPUs, it becomes a critical necessity to squeeze every bit of these hardware capabilities to make the data science experiment iterations faster and more productive. In this article, we will be exploring various possibilities with Tensorflow (2.2).
Generally, in most cases, data can be made available from multiple sources in many varying formats which include image, text, CSV, server log files, videos, audio files, etc. To make things easier, the Tensorflowtf.data module can be easily customized to consume this data efficiently and send it to the model for further computations.
Before getting started, let’s understand briefly about the tf.data.Dataset in tensorflow. tf.data module provides us with a tf.data.Dataset abstraction represents a sequence of elements, in which each element consists of one or more components, which can be used as a source to consume data. For example, in a spam classification data pipeline, a single element can be composed of two different components representing text data and its label as spam or legitimate. Once we will have our tf.data.Dataset ready, we can use it as our data pipeline. tf.data.Dataset behaves as a python iterator, which can be easily accessed using a python ‘for’ loop.
Dealing with CSV data - Big, Small or Huge
CSVs are widely used as a standard format for exporting/transferring tabular data from source tables and source applications due to their simplicity and compactness. It has a lot of support from open source libraries and it can be easily exported within many commonly used databases.
For example, Let’s say we are using Postgresql as our database for storing tabular data. Then from the psql command line, we can easily export CSV data using the below command:
\COPY table_name TO 'filename.csv' CSV HEADER
Now, In order to consume CSV data through Tensorflow, we will look into various ways that can be used to create a data pipeline for a CSV dataset. Once we have some good intuition about all the possibilities, we will dive more deeper into some best practices to create a production grade highly optimized and scalable data pipeline using Tensorflow.
Method 1:
Using tf.data.Dataset.from_tensor_slices :
Let’s say we have a CSV dataset sample.csv, which is small enough to fit in memory. Once we have loaded it into memory as a Dataframe through pandas, then we can use Dataset.from_tensor_slices to convert our Dataframe object to tf.data.Dataset after which we can easily feed it into a Tensorflow model. Let’s look at the code illustration to get a better understanding of how our pipeline will look like.
Step 1: Let’s create a sample.csv data for the demonstration purpose. We will be using pandas for csv data manipulation. Below we are writing our sample data to the current working directory. Please update the file path if needed (taking care of the absolute/relative paths).
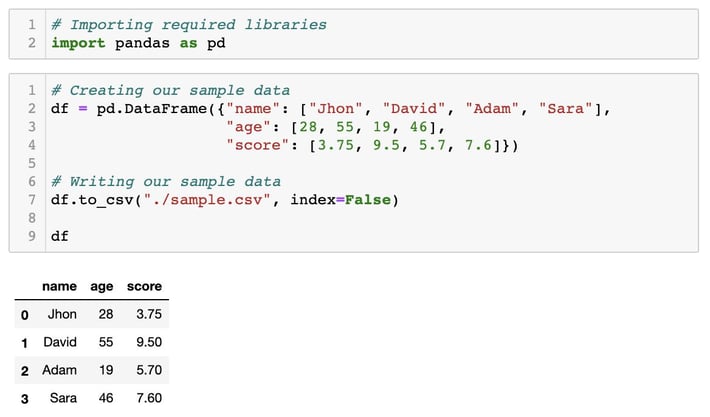
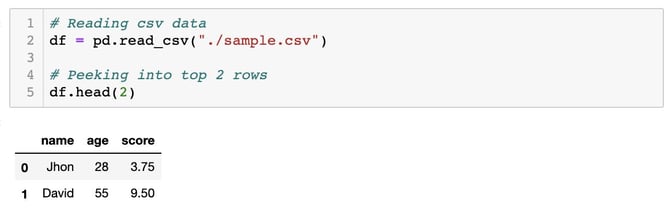
Step 2: Read sample.csv file through pandas. Depending upon whichever CSV data you’ll be using, please update the file path if needed (taking care of the absolute/relative paths).
Step 3: Converting the Dataframe to tf.data.Dataset object.

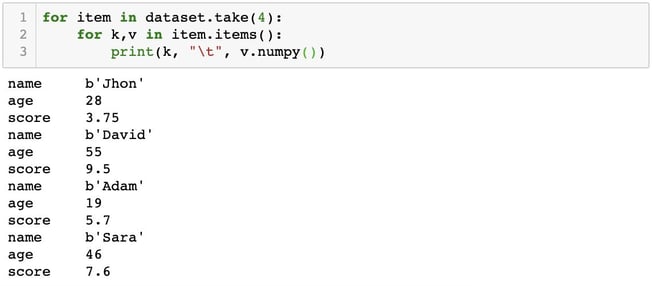
Step 4: Peeking into 4 elements of our tf.data.Dataset object. Below, we are using .numpy() method to convert the tensors into numpy arrays.
Pros:
- Easy to use
- Recommended for small datasets (size <1GB)
Cons:
- Not efficient when dealing with huge amounts of data.
- Before consuming, data needs to be loaded inside memory, which may lead to OOM (out of memory) error in case of large datasets.
- Lots of memory wastage, may run into the 2GB limit for tf.GraphDef protocol buffer.
Method 2:
Using tf.data.Dataset.from_generator :
Here we will be using the tf.data.Dataset.from_generator method which is quite efficient as compared to the previously discussed tf.data.Dataset.from_tensor_slices method. tf.data.Dataset.from_generator provides a very convenient way to use the python generators for consuming the dataset. With the use of a python generator, one can easily create any transformation in pure python as a part of the data pipeline and can use the transformation on-the-go during data consumption. Below code shows how we can use the python generator to consume the CSV dataset.
Step 1: Importing required libraries like tensorflow and CSV.
 Step 2: Creating a python generator for reading a CSV dataset row-wise, one at a time. This prevents loading the entire dataset in the memory at the same time, due to which it is quite a memory efficient. Below we are using sample.csv dataset assuming it lies in the same directory where our notebook resides. Feel free to update the file path accordingly. Also, we are skipping 1 row to ignore the headers/columns.
Step 2: Creating a python generator for reading a CSV dataset row-wise, one at a time. This prevents loading the entire dataset in the memory at the same time, due to which it is quite a memory efficient. Below we are using sample.csv dataset assuming it lies in the same directory where our notebook resides. Feel free to update the file path accordingly. Also, we are skipping 1 row to ignore the headers/columns.

Step 3: Using tf.data.Dataset.from_generator module to convert our generator to tf.data.Dataset object. We are passing our generator as a first argument and type of the output value as a second argument. Since the values in our sample dataset are name, age, and score, thus we are using tf.string name, tf.int8 age, and tf.float16 for a score as output types respectively. Precision type for ints and floats needs to be adjusted depending on the range of values a particular column takes.

Step 4: Peeking into 4 samples of our tf.data.Dataset dataset. Below, we are using .numpy() method to convert the tensors into numpy arrays.

Pros:
- Simple, flexible and easy to use due to pure pythonic notations.
- Memory efficient
Cons:
- Limited portability and scalability as a python based generator will be running in the same python process due to GIL lock.
Method 3:
Using tf.data.experimental.make_csv_dataset :
Let’s say we have a csv file train.csv as our dataset having columns [id, x1, x2, x3, x4, t] where x’s are feature columns, id is the unique identifier column for each record and t is the target column for some classification/regression problem. Now to consume this data, we can use tf.data.experimental.make_csv_dataset with below procedures. Once we have our pipeline ready, it will return tf.data.Dataset type which can be directly fed inside any Tensorflow model.
Below is the code illustration:
Step 1: Importing required libraries

Step 2: Checking out current tensorflow version

Step 3: Creating our own wrapper for data loading with Tensorflow
Note: Here in below code, we are using a shuffle_buffer_size = 10000 which means the shuffling will be done inside each 10000 samples at a time, which will lead to poor shuffling in case the data source has more than 10000 rows. So, in such cases, the recommended size for shuffle_buffer_size should be at least the size of the data source, so that entire data can be shuffled properly. If the memory buffer for the size of the data needed is larger than the available hardware memory capacity, then in such case it is advised to do the shuffling procedure manually during the data preparation phase using pandas, numpy, scipy, etc., and use the resultant shuffled data as a source.

Step 4: Reading data from our train.csv. We will be using the titanic dataset for the demonstration purpose. Do refer to kaggle for downloading the titanic dataset. Once it's downloaded, it needs to be in the same directory where the notebook resides. Feel free to update the file path as needed. After that, we can run below codes to consume our downloaded csv dataset. Below, we are using .numpy() method to convert the tensors into numpy arrays.

Tensorflow Documentation for make_csv_dataset() method
Pros:
- Easy to use
- Works much better for both small as well as large datasets.
Cons:
- Still an experimental module
Method 4:
Using tf.data.TFRecordDataset :
The tf.data API provides another method tf.data.TFRecordDataset, which can be used to consume any amount of data in the most efficient way as an tf.data.Dataset object. tf.data.TFRecordDataset is a record-oriented binary format that is optimized for high throughput data retrieval and can be used for consuming any data format. We can use tf.data.TFRecordDataset class to build a streaming input pipeline that can stream over the content of one or more TFRecord files.
Tensorflow recommends serializing and storing any dataset like CSVs, Images, Texts, etc., into a set of TFRecord files, each having a maximum size of around 100-200MB. In order to do so, we have to create a writer function using TFRecordWriter that will take any data, make it serializable and write it into TFRecord format.
To get the data back in original format during the training time, we will create another reader function which will take the written TFRecord files and convert them back into their original form.
Now for serializability, there are two options:
- Using
tf.Examplein the case of scalar features - Using
tf.serialize_tensorin the case of non-scalar features
Let’s look at the below steps to get a good understanding of how to achieve this.
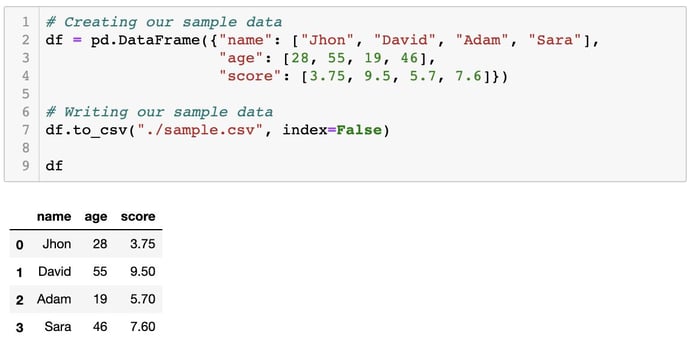
Step 1: Importing required libraries and creating our sample data

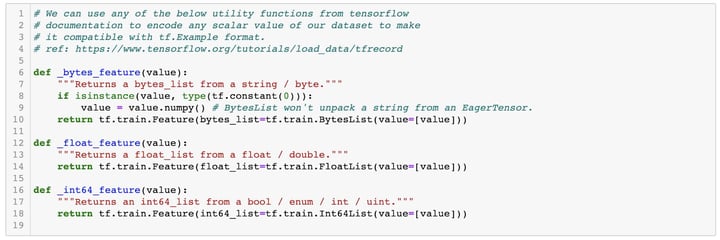
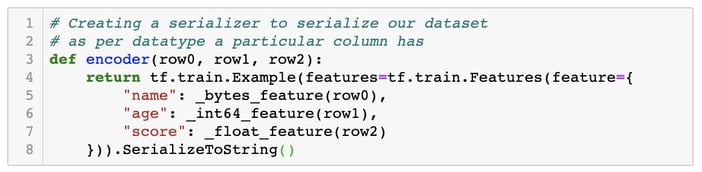
Step 2: Create a utility function and encoder to make each element of our dataset compatible for tf.Example
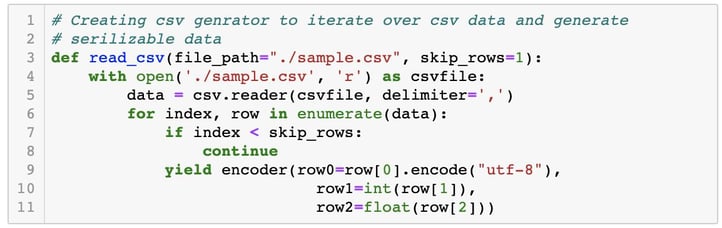
Step 3: Create a CSV reader using a generator to initially read it, make it serializable, and then pass it to a writer function.
Step 4: Create a writer function to finally write the encoded data received from the above CSV reader, into a TFRecord file format.

Step 5: Create a decoder function to decode the TFRecord data at the time of consumption as an tf.data.Dataset object. Here we are decoding it as the same data type that it was originally in our CSV dataset. Do take caution here to create a correct data type mapping during decoding.

Step 6: Now we can directly read our TFRecord dataset using tf.data.TFRecordDataset method which will return tf.data.Dataset object.

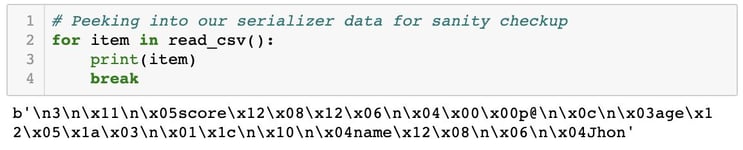
Step 7: Peeking into the first 2 records of our dataset

Pros:
- Highly efficient, scalable and optimized for Tensorflow environments.
- Works much better for all big, small as well as massive datasets.
Cons:
- Little cumbersome to implement
This concludes the various methods that we can use to consume the most widely used dataset type, which is a CSV. Now as we have a good understanding of various pros and cons of all the above-discussed methods, we can easily decide the appropriate application of each of these. Depending upon the requirements, we can use any one of them, but considering the scalability and efficiency of a data pipeline, method 4 is the recommended one that can be used.
Once we have our tf.data.Dataset ready to consume, there are plenty of other things to consider to make the consumption more efficient. Below are some of the key things to consider when consuming the tf.data.Dataset:
- Use .
prefetch()to make sure that data is available for the GPUs or TPUs when the execution is completed for a batch so that hardware accelerators will not have to sit idle to wait for the next batch to load in memory - Use
.interleave()with parallelism for the transformation of the dataset, if transformation is needed at the time of the consumption phase. Otherwise, it is better to carry out transformation during the TFRecords preparation phase. Also, do look if deterministic criteria are needed or not, else settingdeterministic=Falsecan lead to more performance optimization. - Use
.cache()to cache some computations like transformation which may be overlapping during each epoch. This can give a significant boost in efficiency.
For more information, one can explore tensorflow documentation.